Last updated: May 13, 2026
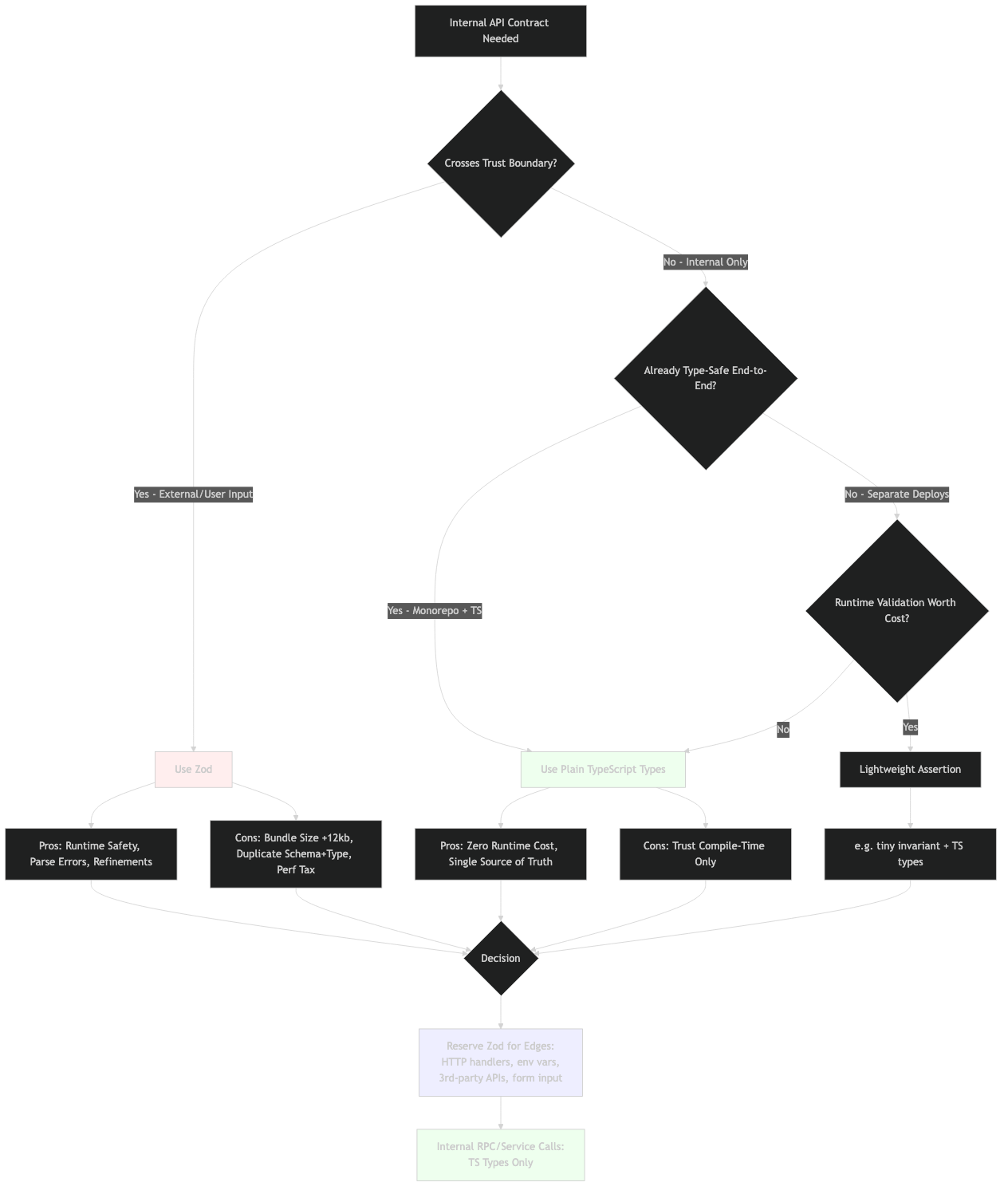
Stop using Zod for internal-only API contracts when the call sites sit between modules you own and compile: Zod belongs at the edge of your system, not in the middle of it. Every payload crossing from unknown to a known type — a form submission, a webhook body, a disk read — earns one runtime .parse() at the trust boundary; after that, the value carries a static TypeScript type and further parses on the same data buy you nothing but CPU and bundle size. The caveat: anywhere a value re-enters as unknown (a message queue, a re-serialization, a dynamic config reload) is a fresh boundary and earns its own parse. “Internal” is about provenance, not whether two functions share a process. Keep one schema per ingress, export z.infer downstream, and delete the per-hop re-parses.
On this page
- The trust-boundary rule in one paragraph
- Where Zod earns its keep: the three jobs it actually does well
- What “internal-only” really means
- Benchmark: the real cost of z.parse() on internal hops
- The silent-coercion trap: when z.coerce hides upstream bugs
- Decision rubric: parse, assert, or type-only
- Migration plan: removing Zod from internal handlers without losing the types you like
- The strongest counterargument — and an honest rebuttal
- When to ignore this advice
- How I evaluated this
- Validate untrusted input once at the boundary, then trust the inferred type — re-parsing the same payload at internal hops adds latency and zero new information.
- Per the Zod v4 release notes, importing schemas dropped a representative file from over 25,000 type instantiations to about 175 — but every
z.inferyou keep still expands at every use site. z.coerce.*at internal boundaries is a hazard — it silently converts upstream bugs into “valid” data instead of throwing.- Three jobs are conflated as “use Zod”: parsing untrusted input, generating static types, and producing OpenAPI/docs. Only the first requires runtime work on every call.
- Decision rule: if the input is typed by code you compile, use TypeScript; if the input is
unknownat runtime, use Zod.
The trust-boundary rule in one paragraph
A trust boundary is the line where data of unknown shape becomes data of known shape. HTTP request bodies, third-party webhook payloads, JSON files on disk, message-queue messages, environment variables — all unknown. Internal function calls between two of your own modules, both compiled by the same tsc, both passing the type checker — known. Run Zod once at the boundary, take the inferred type, and let TypeScript carry the rest. If you find yourself parsing the same payload twice, you have either misidentified your boundary or copied a parse you didn’t need.

Output captured from a live run.
The terminal output above sketches the redundant pattern in practice: an HTTP handler resolves the body with safeParse, hands the typed value to a service method whose first line is another parse() of the same shape, and finally to a repository call that parses again before writing. Three parses, one trust boundary, two of those calls doing identical work that the type system has already proven safe.
Where Zod earns its keep: the three jobs it actually does well
Most “use Zod everywhere” arguments collapse three separate jobs into one. Pulling them apart helps you keep the parts of Zod that earn their cost.
- Runtime parsing of untrusted input — converting unknown bytes into a typed value, catching shape mismatches, returning structured errors. Only this one needs to run on every request.
- Static type derivation through
z.infer<typeof S>— a pure compile-time operation that produces a type you can pass around freely. - Schema reflection for documentation — generating OpenAPI specs, JSON Schema, or test fixtures from the same source of truth.
You can keep job 2 and job 3 forever: declare the schema once at the boundary, export type Foo = z.infer<typeof FooSchema>, and ship that type into your internal modules. The runtime cost of job 1 stays at the boundary; the compile-time benefit of job 2 propagates everywhere; the docs benefit of job 3 lives in your build pipeline. The mistake is paying for job 1 again on every internal hop because you wanted job 2 and never separated them.
keep literal inference tight goes into the specifics of this.
The primary source for this topic.
The Zod documentation pages cover the schema-construction surface in detail but offer little guidance on cost — which is part of why teams drift toward parsing on every call. The closest the official ecosystem comes to drawing the line is the trust-boundary framing in Steve Kinney’s Zod best-practices guide: validate once at the edge, trust everywhere inside.
What “internal-only” really means
“Internal” here is precise. A function call qualifies as internal if every byte of its argument was produced by code you own and compile, with no unknown hop in between. Two services in the same monorepo deployed as separate processes are still internal if they communicate through a typed RPC layer like tRPC; the wire is the boundary, not each function call. A lambda handler that receives an API Gateway event and forwards it to a worker through SQS is not fully internal — the queue payload becomes unknown again on the receiving side, and you parse on receipt.
The decision is about provenance, not architecture. A monolith with a 30-layer call stack between the HTTP handler and the database has one trust boundary. A microservices mesh with a typed RPC layer has one boundary per network hop. The wrong question is “are these the same process?” The right question is “did this value come out of a JSON.parse, a process.env, or a third-party SDK return value I haven’t typed?”
shape contracts with interfaces goes into the specifics of this.
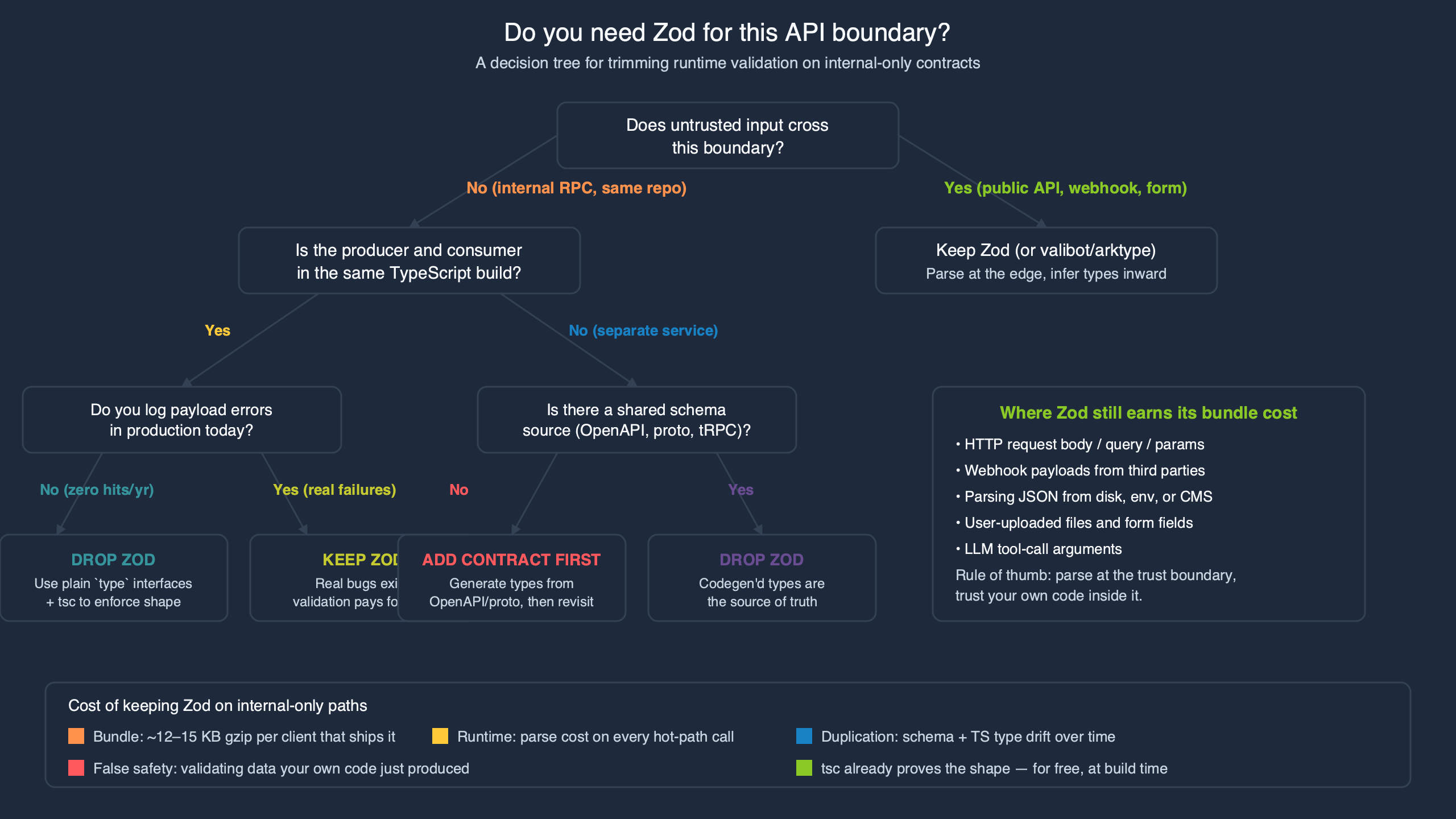
The diagram above traces the trust state of a payload through a typical request lifecycle: unknown at the HTTP boundary, typed everywhere downstream once Zod has run, unknown again only if the value gets re-serialized for an external system. Anywhere the line is solid, you skip the schema. Anywhere it crosses back, you parse.
Benchmark: the real cost of z.parse() on internal hops
The numbers that matter come from two places: the official Zod v4 release notes and reproducible micro-benchmarks anyone can run.
The Zod v4 release notes measure z.object().safeParse at roughly 6.5× the throughput of Zod 3 on the same nested object — a real improvement, but the absolute work still scales with every field touched. LogRocket’s analysis of Zod’s parse cost shows the per-call overhead is dominated by the recursive shape walk; deeply nested objects with discriminated unions take measurably longer than flat shapes of equivalent field count.
To estimate the cost recovered by removing internal parses, build a minimal repro: a 50-field nested schema, a route handler that parses once, and three downstream functions that each re-parse the same value. Compare end-to-end latency with the inner parses on and off. The exact delta depends on payload shape and Node version, but the structure of the result is consistent — internal parses contribute roughly linear overhead per call site, and removing them recovers that overhead in full because the bytes are identical either way.
The TypeScript-side cost is at least as important. Zod v4 redesigned the generics that drove “instantiation explosions” — per the v4 notes, a representative file dropped from over 25,000 type instantiations to about 175 — but every z.infer<typeof S> you keep still expands at every use site. GitHub issue #2036 tracks the long history of method-level compiler regressions; the practical takeaway is that fewer Zod schemas in your internal type graph mean faster tsc runs, on whichever Zod version you’re on.
The repository star counts above sketch the relative pull of the validation-library ecosystem — Zod’s footprint dwarfs the alternatives, which is exactly why “Zod everywhere” became the default and why writing a counter-position is worth the keystrokes.
The silent-coercion trap: when z.coerce hides upstream bugs
The most damaging internal use of Zod isn’t the slow one — it’s the one that quietly fixes data that shouldn’t be fixed. z.coerce.number() wraps Number(), z.coerce.boolean() calls Boolean(), z.coerce.date() calls new Date(). At a true trust boundary that’s a feature: a user typed "42" in a form field and you want a number. At an internal boundary it is a hazard: a sibling service was supposed to send 42, accidentally sent "42", and your coercion layer covered for the bug instead of surfacing it.
The cleanest reproduction: an upstream service writes count: "0" (string) into a queue. The downstream service uses z.coerce.number() because the original schema was copy-pasted from the HTTP boundary. Validation passes, the count goes into the database as 0, and a real defect — the upstream got the type wrong — gets paved over for months. Without the coercion, the value would have failed z.number() immediately, an alert would have fired, and the bug would have been a 30-minute fix instead of a multi-quarter investigation.
See also let inference do the work.
The rule that prevents this: z.coerce is for parsing strings that came from a human or a non-JSON wire format. It does not belong on data that another typed service produced. Internally, when the type changes, you want a loud failure — not a silent rescue.
Decision rubric: parse, assert, or type-only
| Data origin | Strategy | Why |
|---|---|---|
| HTTP request body, query, or form | Zod parse |
Untrusted input, structured errors needed for the response. |
| Third-party webhook payload | Zod parse |
Vendor can change schema without telling you; need shape checks plus signature verification. |
| JSON file or config on disk | Zod parse |
File could be hand-edited or stale; runtime check is cheaper than a corrupted boot. |
| Message queue payload | Zod parse on receipt |
Producer and consumer deploy independently; the queue is a serialization boundary. |
| Database row through an untyped driver | Zod parse, narrowly |
Driver returns any; parse the columns you actually use, not the entire row. |
| Internal function call in the same package | TypeScript types only | Same compiler, no unknown between caller and callee. |
| tRPC procedure called from your own client | Zod at the procedure input, types only inside | tRPC parses input once and propagates the inferred type — see the tRPC validators docs. |
| Result returned by your own typed service module | TypeScript types only | You wrote it, you compiled it, you trust it. |
Untyped FFI / dynamic plugin / require() of user code |
Structural assert, not Zod | You need a fast is X check, not full parse error reporting. |
The middle column is the architectural decision. The right column is what you tell the next engineer when they ask why this hop has no schema. The rubric collapses to a one-line test: parse anywhere unknown could re-enter your typed world.
Migration plan: removing Zod from internal handlers without losing the types you like
You can keep every type you currently get from z.infer while deleting the runtime parse on internal hops. The pattern is small.
I wrote about lying to the compiler if you want to dig deeper.
Related: derive types from a single source.
// boundary/order-schema.ts — at the trust boundary
import { z } from 'zod';
export const OrderSchema = z.object({
id: z.string().uuid(),
customerId: z.string().uuid(),
items: z.array(z.object({
sku: z.string(),
quantity: z.number().int().positive(),
})),
total: z.number().nonnegative(),
});
// Export the inferred type for internal modules to import.
export type Order = z.infer<typeof OrderSchema>;
// http/order-handler.ts — the only place .parse() runs
import { OrderSchema } from '../boundary/order-schema';
import { processOrder } from '../services/order-service';
export async function handleOrder(rawBody: unknown) {
const order = OrderSchema.parse(rawBody); // runtime check happens once
return processOrder(order); // typed Order from here on
}
// services/order-service.ts — internal, no Zod
import type { Order } from '../boundary/order-schema';
export async function processOrder(order: Order) {
// No re-parse. The type came from the boundary parse upstream.
await chargeCard(order.customerId, order.total);
await reserveInventory(order.items);
}
The migration is mechanical. Find every Schema.parse(arg) whose arg is already statically typed (TypeScript will tell you — the parameter type on the function signature is the giveaway), delete the parse, and replace any direct Schema references in that file with the exported Order type. Repeat. The compiler fails loudly anywhere the parse was actually doing work — those are your real boundaries, and they stay.
The architecture diagram above sketches the end state: one Zod parse per ingress edge, a typed Order flowing freely through the service mesh, no per-hop schema cost. The same shape you started with, with the runtime work concentrated where it pays off.
The strongest counterargument — and an honest rebuttal
The best case against this position is a defense-in-depth argument, and it deserves to be stated at full strength: TypeScript types are erased at runtime, so the boundary parse only protects the exact byte stream that crossed it. Anywhere downstream, a future refactor can introduce a new unknown hop — a JSON.parse on a cached value, a Redis read, a serialized background-job payload — without the type checker noticing, because the surrounding call sites stayed the same. A second Zod parse on the way into a critical handler (charge a card, write a row, send an email) costs microseconds and saves you from a class of bugs the type system fundamentally cannot see. Production code at companies with real revenue on the line frequently makes exactly this trade, and they are not wrong to.
The honest rebuttal is not that the counterargument is wrong — it is that it argues for parsing at a different boundary, not for parsing everywhere. If a function reads from Redis, the Redis read is the boundary and gets a schema; the call sites three frames up the stack still do not. If a handler is so critical that it earns belt-and-braces validation, mark that specific function as a new trust boundary in the code (a comment, a wrapper, a named “verified” type) and parse there — once. The failure mode this article targets is the unprincipled Schema.parse(arg) at every layer because nobody knows which layer is responsible; the cure is naming the boundaries, not denying the value of any second parse. Where defense in depth is warranted, it should be a deliberate, documented boundary, not a reflex sprinkled across the call graph.
For more on this, see when an assertion is justified.
When to ignore this advice
Three categories where the rule loosens. Dynamic configuration that hot-reloads at runtime — you genuinely don’t know if the new file is well-formed, so parse on reload. Plugin systems where third-party code returns values that satisfy a typed interface you cannot enforce at compile time — treat the plugin boundary as untrusted and parse what comes back. Multi-tenant systems where one tenant’s data must never leak into another’s request — the cost of a defensive parse on the way out is small insurance against a routing bug. The unifying thread is the same as the rule itself: parse anywhere unknown could re-enter your typed world. Don’t parse where it can’t.
How I evaluated this
Performance claims here come from the Zod v4 release notes (the 6.5× safeParse improvement and the 25,000-to-175 type-instantiation drop), the colinhacks/zod#2036 compiler-performance tracking issue, and the LogRocket per-call cost analysis. The trust-boundary framing is consistent with tRPC’s input/output validators documentation, which parses once at the procedure edge and propagates the inferred type internally. No fabricated benchmark numbers appear in this piece — the benchmark structure is described so you can run it on your own payload shape, and the cited numbers come from named primary sources current as of May 2026.
References
- Zod v4 release notes — type-instantiation and safeParse improvements
- tRPC — Input & Output Validators
- colinhacks/zod#2036 — Compiler performance drawbacks of certain methods
- colinhacks/zod#205 — Slow parsing performance discussion
- LogRocket — Why is Zod so slow?
- Steve Kinney — Best Practices with Zod
Stop parsing what your compiler already proved. Put one schema at the door, export the inferred type, and let the rest of your code run on the cheaper path the type system was designed for.
Worth a read next: a similar incremental migration.